Bu doküman ingilizce dokümana göre eski olabilir. Son güncellemeler için lütfen İngilizce Dokümanı. ziyaret edin
Üretim ortamı en iyi pratikleri: performans ve güvenilirlik
Genel bakış
Bu makalede üretim ortamına dağıtılımış Express uygulamaları için en iyi performans ve güvenilirlik pratikleri anlatılıyor.
Bu konu açıkça her iki geleneksel geliştirme ve operasyonları da kapsayarak “devops” dünyasına girer. Buna göre, buradaki bilgiler iki kısma ayrılmıştır:
- Kodunuzda yapılacak şeyler (geliştirme kısmı):
- Ortamınızda / kurulumunuzda yapılacak şeyler (operasyon kısmı):
Kodunuzda yapılacak şeyler
Uygulamanızın performansını iyileştirmek için yapabileceğiniz bazı şeyler:
gzip sıkıştırma kullan
Gzip sıkıştırma, yanıt gövdesininin boyutunu büyük ölçüde azaltabilir ve dolayısıyla da web uygulamanın hızını arttırır. Express uygulamanızda gzip sıkıştırması için compression ara yazılımını kullanın. Örnek olarak:
const compression = require('compression')
const express = require('express')
const app = express()
app.use(compression())
Üretim ortamındaki yüksek-trafikli bir website için yapılabilecek sıkıştırmanın en iyi yolu ters proxy sevisyesinde uygulamaktır (bakınız Ters proxy kullanımı). Bu durumda sıkıştırma ara yazılımı kullanmak zorunda değilsiniz. Nginx’te gzip sıkıştırmayı devreye alma hakkında daha fazla detay için Nginx dökümantasyonuna bakınız ngx_http_gzip_module modülü.
Senkron fonksiyonlar kullanma
Senkron fonksiyon ve metodlar kod çalıştırma sürecini bir şey döndürene kadar tutarlar. Senkron bir fonksiyona yapılacak bir çağrı birkaç mikrosaniye veya milisaniye içinde dönerler, ancak yüksek-trafikli websitelerde bu çağrılar toplanıp uygulamanın performansını düşürürler. Üretim ortamında bu kullanımdan uzak durun.
Node ve birçok modül kendi fonksiyonlarının senkron ve asenkron versiyonlarını sunmalarına rağmen, üretim ortamında her zaman asenkron versiyonları kullanın. Senkron bir fonksiyonun kullanımının haklı olabileceği tek zaman uygulamanın ilk başlangıcıdır.
Node.js 4.0+ veya io.js 2.1.0+ kullanıyorsanız, uygulamanız senkron bir API kullandığında bir uyarı ve yığın izleme (stack trace) yazdırmak için --trace-sync-io komut satırı bayrağını kullanabilirsiniz. Elbette bunu üretim ortamında kullanmak istemezsiniz, daha çok bunu kodunuzun üretim için hazır olduğundan emin olmak için. Daha fazla bilgi için bakınız: node komut satırı seçenekler dökümantasyonu.
Loglamayı doğru yap
Genelde, uygulamanızdan loglama yapmak için iki neden vardır: Hata ayıklama ve uygulama aktivitesini loglama için (yani, diğer her şey). Geliştirme ortamında log mesajlarını terminale yazdırmak için console.log() veya console.error() kullanmak yaygın bir kullanımdır. Ancak hedef bir terminal veya dosya olduğunda bu fonksiyonlar senkrondur, dolayısıyla, çıktıyı başka bir programa aktarmadığınız sürece bunlar üretim ortamı için uygun değiller.
Hata ayıklamak için
Hata ayıklama amacıyla loglama yapıyorsanız, o zaman console.log() yerine debug gibi özel bir hata ayıklama modülü kullanın. Bu modül, console.error() fonksiyonuna gönderilecek mesajları kontrol etmek için DEBUG ortam değişkenini kullanmanızı sağlar. Uygulamanızı sade asenkron halde tutmak istiyorsanız, yine console.error() çıktılarını başka bir programa aktarmanız gerekir. Ama yine de, üretim ortamında hata ayıklamayacaksınız, değil mi?
Uygulama aktivitesi için
Uygulama aktivitesini logluyorsanız (örneğin trafik izleme veya API çağrıları), console.log() yerine Winston veya Bunyan gibi bir loglama kütüphanesi kullanın. Bu iki kütüphanenin detaylı bir karşılaştırması için, StrongLoop blog yazısına bakınız Winston ve Bunyan Node.js Loglama Karşılaştırması.
İstisnaları düzgün işle
Node uygulamaları yakalanmamış istisnalar ile karşılaştıklarında patlarlar. İstisnaları işlememe ve gerekli aksiyonları almama Express uygulamanızın patlamasına ve çevrimdışına çıkmasına neden olur. Aşağıdaki Uygulamanızın otomatik olarak yeniden başlatıldığından emin olma tavsiyesine uyarsanız, o zaman uygulamanız bir çökmeden tekrar ayağa kalkabilir. Neyse ki Express uygulamalarının tipik olarak kısa bir başlama süresi var. Yine de patlamalardan kaçınmak gerekir ve bunu yapmak için de istisnaları uygun bir şekilde işlemeniz gerek.
Tüm istisnaları işlediğinizden emin olmak için, aşağıdaki teknikleri kullanın:
Bu konulara girmeden önce Node/Express istisna işleme ile ilgili temel bir anlayışa sahip olmanız lazım: hata-öncellikli geri çağırmaları kullanmak ve hataları ara yazılımda yaymak. Node, asenkron fonksiyonlardan hataları dönmek için “hata-öncellikli geri çağırma” anlayışını kullanır, bu fonksiyonlarda birinci parametre hata objesi ve ondan sonraki parametreleri ise sonuç verileri takip eder. Hata olmadığını belirtmek için ilk parametreye null geçin. İstisnaları anlamlı bir şekilde işlemek için bu geri çağırma fonksiyonlarının hata-öncellikli geri çağırma anlayışını takip etmesi gerek. Ve Express’te ara yazılım zincirinde hataları yaymak için en iyi yöntem next() fonksiyonunu kullanmaktır.
Hata işleme temelleri hakkında daha fazla bilgi için bakınız:
- Node.js’te Hata İşleme
- Güçlü Node Uygulamaları Yazmak: Hata İşleme (StrongLoop blogu)
Ne yapmamalı
Yapmamanız gereken bir şey var, o da bir istisnanın olay döngüsüne kadar çıkarak yayılmasıyla oluşan uncaughtException olayını dinlememek. uncaughtException için bir olay dinleyici eklemek, istisna ile karşılaşan bir sürecin varsayılan davranışını değiştirir; süreç istisna almasına rağmen koşmaya devam edecektir. Bu uygulamanızın patlamasını önlemek için iyi bir yol gibi gözükebilir, ancak uygulamayı yakalanmayan bir istisnadan sonra koşturmaya devam ettirmek tehlikeli bir alıştırmadır ve tavsiye edilmez, çünkü sürecin durumu (state) güvenilmez ve öngörülemez hale gelir.
Ek olarak, uncaughtException kullanımı resmen ham olarak tanınır. Yani uncaughtException olayını dinlemek gerçekten kötü bir fikirdir. Bu yüzden çoklu süreçler ve denetçiler gibi şeyleri tavsiye ediyoruz: patladıktan sonra yeniden başlatma çoğu zaman bir hatayı düzeltmenin en güvenli yoludur.
Ayrıca domains kullanmanızı tavsiye etmeyiz. Genellikle problemi çözmez ve de kullanımdan kaldırılmış bir modüldür.
try-catch kullan
Try-catch senkron kodda oluşan istisnaları yakalamak için kullanabileceğiniz bir JavaScript dili yapısıdır. Try-catch yapısını, örneğin, JSON ayrıştırma hatalarını aşağıda gösterildiği gibi ele almak için kullanın.
Tanımsız değişkenlerde referans hataları gibi kapalı (implicit) istisnaları bulmak için JSHint veya JSLint gibi araçları kullanabilirsiniz.
Buradaki örnek potansyel bir süreç-patlatıcı istisnayı ele alman try-catch kullanımını gösterir. Bu ara yazılım fonksiyonu JSON objesi olan “params” adında bir sorgu alanı parametresi alıyor.
app.get('/search', (req, res) => {
// Simulating async operation
setImmediate(() => {
const jsonStr = req.query.params
try {
const jsonObj = JSON.parse(jsonStr)
res.send('Success')
} catch (e) {
res.status(400).send('Invalid JSON string')
}
})
})
Ancak, try-catch sadece senkron kod için çalışır. Node platformu birincil olarak asenkron olduğundan (özellikle de bir üretim ortamında), try-catch çok fazla istisna yakalamayacaktır.
Promise kullan
Promise’lar then() kullanan asenkron kod bloklarında herhangi bir istisnayı (implicit / explicit) işleyebilir. Sadece .catch(next) ifadesini promise zincirlerinin sonuna ekleyin. Örneğin:
app.get('/', (req, res, next) => {
// do some sync stuff
queryDb()
.then((data) => makeCsv(data)) // handle data
.then((csv) => { /* handle csv */ })
.catch(next)
})
app.use((err, req, res, next) => {
// handle error
})
Şimdi bütün hatalar, asenkron ve senkron olmak üzere, hata işleyici ara yazılıma gider.
Ancak, iki uyarı var:
- Bütün asenkron kodunuz promise döndürmeli (yayıcılar/emitter hariç). Eğer belirli bir kütüphane promise döndürmüyorsa, Bluebird.promisifyAll() gibi bir yardımcı fonksiyon kullanarak temel objeyi dönüştürün.
- Olay yayıcılar (akışlar gibi) yine de yakalanmayan istisnalara neden olabilir. O yüzden hata olayını düzgün bir şekilde ele aldığınızdan emin olur; örneğin:
const wrap = fn => (...args) => fn(...args).catch(args[2])
app.get('/', wrap(async (req, res, next) => {
const company = await getCompanyById(req.query.id)
const stream = getLogoStreamById(company.id)
stream.on('error', next).pipe(res)
}))
wrap() fonksiyonu ret edilen promise’ları yakalayıp birinci argümanı hata olarak next() fonkisyonunu çağıran bir sarıcıdır (wrapper). Detaylar için, bakınız Express’te Promise, Generator ve ES7 ile Asenkron Hata Ele Alma.
Promise’lerle hata ele alma ile ilgili daha fazla bilgi için bakınız Node.js’te Q ile Promis’ler – Geri çağrımalara Bir Alternatif.
Ortamınızda / kurulumunuzda yapılacak şeyler
Uygulamanızın performansını iyileştirmek için sistem ortamınızda yapabileceğiniz bazı şeyler:
- NODE_ENV değerini “production” olarak ayarla
- Uygulamanızın otomatik olarak yeniden başlatıldığından emin ol
- Uygulamanızı bir kümede (cluster) koş
- İstek sonuçlarını önbelleğe al (cache)
- Bir yük dengeleyicisi (load balancer) kullan
- Bir ters proxy kullan (reverse proxy)
NODE_ENV değerini “production” olarak ayarla
NODE_ENV ortam değişkeni bir uygulamanın hangi ortamda koştuğunu belirtir (genellikle development veya production olur). Performansı iyileştirmek için yapabileceğiniz en basit şeylerden biri NODE_ENV değerini “production” olarak ayarlamaktır.
NODE_ENV “production” olarak ayarlandığında Express:
- Görüntü şablonlarını önbelleğe atar.
- CSS uzantılarından oluşturulan CSS dosyalarını önbelleğe atar.
- Daha az ayrıntılı hata mesajları üretir.
Yapılan testler sadece bunu yaparak uygulamanın performansının üç kat arttığını gösteriyor!
Eğer özellikle bir ortam için kod yazmak istiyorsanız, NODE_ENV değişkeninin değerini process.env.NODE_ENV ile kontrol edebilirsiniz. Herhangi bir ortamı değişkeninin değerini kontrol etmenin bir performans düşüşü meydana getirdiğini unutmayın, ve bu yüzden bu işlem idareli yapılmalıdır.
Geliştirme modunda, tipik olarak ortam değişkenlerini interaktif shell’de export veya .bash_profile dosyasınızı kullanarak ayarlayabilirsiniz. Ama genellikle üretim sunucusunda bunu yapmamalısınız; onun yerine, işletim sisteminizin init system’ini kullanabilirsiniz (systemd veya Upstart). Bir sonraki kısım genel init system kullanımı hakkında daha fazla detay veriyor, ama NODE_ENV değişkeninin ayarlanması performans için çok önemli olduğundan (ve yapması da kolay olduğundan) burada vurgulanmıştır.
Upstart ile, job dosyanızda env ifadesini kullanın. Örnek olarak:
# /etc/init/env.conf
env NODE_ENV=production
Daha fazla bilgi için bakınız Upstart Giril, Cookbook ve En İyi Pratikler.
Systemd ile, ünite dosyanızdaki Environment direktifini kullanın. Örnek olarak:
# /etc/systemd/system/myservice.service
Environment=NODE_ENV=production
Daha fazla bilgi için bakınız Systemd Ünitelerindeki Ortam Değişkenlerini Kullanma.
Uygulamanızın otomatik olarak yeniden başlatıldığından emin olun
Üretim ortamında hiçbir zaman uygulamanızın çevrimdışı kalmasını istemezsiniz. Bu, uygulamanızın veya sunucunun kendisinin patlaması durumunda yeniden başlatıldığından emin olmanız gerektiği anlamına gelir. Bu olaylardan hiçbirinin olmamasını ummanıza rağmen, gerçekçi olarak her iki olasılığı da hesaba katarak:
- Patladığında uygulamayı (ve Node’u) yeniden başlatmak için bir süreç yöneticisi kullanmak.
- İşletim sisteminiz tarafından sağlanan init system’i kullanarak, işletim sistemi çöktüğünde yeniden başlatmak. Init system’i bir süreç yöneticisi olmadan da kullanabilirsiniz.
Node uygulamaları yakalanmayan bir istisna ile karşılaştıklarında patlarlar. En başta yapmanız gereken şey uygulamanızın iyi test edilmiş olmasını ve bütün istisnaları (detaylar için bakınız istisnaları düzgün bir şekilde ele almak) ele aldığını sağlamaktır. Ancak yine de tedbir olarak, uygulamanız patlarsa ve patladığında, yeniden başlatılacağını sağlayan bir mekanizmayı yapmak.
Süreç yöneticisi kullan
Geliştirme ortamında, uygulamanızı basitçe komut satırından node server.js veya benzeri bir şeyle başlatırsınız. Ama bunu üretim ortamında yapmak, felakete davetiye çıkarmaktır. Uygulama patladığında, siz tekrar başlatana kadar çevrimdışı kalacaktır. Patladığında uygulamanızın yeniden başlatılmasını sağlamak için bir süreç yöneticisi kullanın. Süreç yöneticisi, uygulamaların dağıtımını (deployment) kolaylaştırıan, yüksek kullanılabilirlik sağlayan ve uygulamayı çalışma zamanında yönetmeye imkan sağlayan konteynerlardır.
Uygulamanızın patladığında tekrar başlatılmasına ek olarak, bir süreç yöneticisi aşağıdakileri yapabilmenizi sağlar:
- Çalışma zamanı performansı ve kaynak tüketimi hakkında içgörüler elde edebilme.
- Performansı iyileştirmek için ayarları dinamik olarak değiştirme.
- Cluster kontrolü (StrongLoop PM ve pm2).
Node için en popüler süreç yöneticileri aşağıdakilerdir:
Bu üç süreç yöneticisinin özellik bazında bir karşılaştırması için bakınız http://strong-pm.io/compare/.
Uygulamanız zaman zaman patlasa bile, bu süreç yöneticilerinden birini kullanmanız uygulamanızı ayakta tutmak için yeterli olacaktır.
Ancak, StrongLoop süreç yöneticisi özellikle üretim dağıtımını hedefleyen birçok özelliğe sahiptir. Bunları ve ilgili StrongLoop araçlarını aşağıdakileri yapmak için kullanabilirsiniz:
- Uygulamanızı lokal olarak derleyip paketlemek, ve daha sonra güvenli bir şekilde üretim sisteminize dağıtmak.
- Herhangi bir nedenden dolayı uygulamanız patladığında otomatik olarak yeniden başlatmak.
- Kümelerinizi (cluster) uzaktan yönetmek.
- Performansı iyileştirmek ve bellek sızıntılarını teşhis etmek için CPU profillerini ve heap anlık görüntülerini görüntülemek.
- Uygulamanız için performans ölçülerini görüntülemek.
- Nginx yük dengeleyici için entegre kontrol ile birden çok ana bilgisayara kolayca ölçeklendirmek.
Aşağıda anlatıldığı gibi, init systeminizi kullanarak StronLoop süreç yöneticisini işletim sistemi servisi olarak yüklediğinizde, sistem tekrar başlatıldığında bu da tekrar başlatılacaktır. Dolayısıyla, uygulamanızın süreçlerini ve kümelerini sonsuza dek beraber ayakta tutacaktır.
Init system kullan
Güvenilirliğin bir sonraki katmanı, sunucu yeniden başladığında uygulamanızın da yeniden başlatılmasını sağlamaktır. Sistemler çeşitli nedenlerle yine de çökebilir. Sunucu patladığında uygulamanızında yeniden başlatıldığından emin olmak için, işletim sisteminizdeki gömülü init system’i kullanın. Bugün kullanımda olan iki ana init system şunlardır: systemd ve Upstart.
Express uygulamanızda init system’i kullanmanın iki yolu var:
- Uygulamanızı bir süreç yöneticisinde koşun, ve süreç yöneticisini bir servis olarak init system’le yükleyin. Süreç yöneticisi, uygulamanız patladığında yeniden başlatacaktır, ve işletim sistemi de yeniden başlatıldığında, init system süreç yöneticisini başlatacaktır. Tavsiye edilen yaklaşım budur.
- Uygulamanızı (ve Node’u) direkt olarak init system ile koşun. Bu biraz daha basittir, ama süreç yöneticisini kullanmanın verdiği ek avantajları elde etmiyorsunuz.
Systemd
Systemd, bir Linux sistemi ve servis yöneticisidir. Çoğu büyük Linux dağıtımları varsayılan init system olarak systemd’yi benimsemiştir.
Bir systemd servis konfigürasyon dosyasına unit file denir ve .service dosya ismiyle biter. Aşağıdaki örnek bir Node uygulamasını direkt olarak yöneten bir unit dosyasını gösterir. <angle brackets> ile kapanmış değerleri uygulamanız ve sisteminiz ile değiştirin:
[Unit]
Description=<Awesome Express App>
[Service]
Type=simple
ExecStart=/usr/local/bin/node </projects/myapp/index.js>
WorkingDirectory=</projects/myapp>
User=nobody
Group=nogroup
# Ortam değişkenleri:
Environment=NODE_ENV=production
# Birden fazla gelen bağlantıya izin ver
LimitNOFILE=infinity
# Hata ayıklama için temel dökümlere (core dump) izin ver
LimitCORE=infinity
StandardInput=null
StandardOutput=syslog
StandardError=syslog
Restart=always
[Install]
WantedBy=multi-user.target
Systemd ile ilgili daha fazla bilgi için bakınız systemd referansı (kılavuz).
systemd servisi olarak StrongLoop PM (süreç yöneticisi)
StrongLoop süreç yöneticisini systemd servisi olarak kolaylıkla yükleyebilirsiniz. Bunu yaptıktan sonra, sunucu yeniden başlatıldığında, StrongLoop süreç yöneticisini de otomatik olarak başlatılacak, ve bu da StrongLoop tarafından yönetilen bütün uygulamaların yeniden başlatılmasını sağlayacak.
StrongLoop süreç yöneticisini bir systemd servisi olarak yüklemek için:
$ sudo sl-pm-install --systemd
Daha sonra, servisi başlatmak için:
$ sudo /usr/bin/systemctl start strong-pm
Daha fazla bilgi için bakınız Üretim hostu kurmak (StrongLoop dökümantasyonu).
Upstart
Upstart, birçok Linux dağıtımında bulunan sistem başlangıcında görevleri ve servisleri başlatan, kapanma sırasında kapatan ve denetleyen bir sistem aracıdır. Express uygulamanızı veya süreç yöneticinizi bir servis olarak yapılandırabilirsiniz ve bunlar patladığında, Upstart otomatik olarak yeniden başlatacaktır.
Bir Upstart servisi, .conf uzantılı bir job konfigürasyon dosyasında (“job” olarak adlandırılır) tanımlanır. Aşağıdaki örnek, ana dosyası /projects/myapp/index.js konumunda bulunan “myapp” adında bir uygulama için “myapp” adında bir job yaratmayı gösterir.
Aşağıdakileri içererek /etc/init/ konumunda myapp.conf adında bir dosya yaratın (kalın yazıları sisteminizin ve uygulamanızın değerleriyle değiştirin):
# Sürecin ne zaman başlayacağı
start on runlevel [2345]
# Sürecin ne zaman duracağı
stop on runlevel [016]
# Daha fazla isteği işleyebilmek için dosya tanımlayıcı sınırını artır
limit nofile 50000 50000
# production modunu kullan
env NODE_ENV=production
# www-data olarak koş
setuid www-data
setgid www-data
# Uygulamanın dizininden koş
chdir /projects/myapp
# Başlatılacak süreç
exec /usr/local/bin/node /projects/myapp/index.js
# Süreç çöktüğünde yeninden başlat
respawn
# Yeniden başlatma girişimini 10 saniye içinde 10 kez ile sınırla
respawn limit 10 10
NOT: Bu kod Ubuntu 12.04-14.10’da desteklenen Upstart 1.4 ve üstüne ihtiyaç duyar.
Job, sistem başladığında koşması için yapılandırıldığından uygulamanız da işletim sistemiyle beraber başlayacak, ve sistem çöktüğünde veya uygulama patladığında otomatik olarak yeniden başlatılacaktır.
Uygulamanın otomatik olarak yeniden başlatılmasının yanından, Upstart aşağıdaki komutları da kullanmanızı sağlar:
start myapp– Uygulamayı başlatrestart myapp– Uygulamayı yeniden başlatstop myapp– Uygulamayı durdur
Upstart ile ilgili daha fazla bilgi için bakınız Upstart Giriş, Kılavuz and En İyi Pratikler.
Upstart servisi olarak StrongLoop süreç yöneticisi
StrongLoop süreç yöneticisini bir Upstart servisi olarak kolaylıkla yükleyebilirsiniz. Bunu yaptıktan sonra, sunucu yeninden başladığında StrongLoop süreç yöneticisini otomatik olarak yeniden başlatır, ve süreç yöneticisinin yönettiği bütün uygulamaları da yeniden başlatır.
Strong Loop süreç yöneticisini bir Upstart 1.4 servisi olarak yüklemek için:
$ sudo sl-pm-install
Daha sonra servisi koşmak için:
$ sudo /sbin/initctl start strong-pm
NOT: Upstart 1.4’ü desteklemeyen sistemlerde bu komutlar biraz farklıdır. Daha fazla bilgi için bakınız Production hostu kurmak (StrongLoop dökümantasyonu).
Uygulamanızı bir kümede (cluster) koş
Çok çekirdekli bir sistemde, bir işlemler kümesi başlatarak bir Node uygulamasının performansını birçok kez artırabilirsiniz. Bir küme, uygulamanın birden fazla örneğini koşar, ideal olarak her bir CPU çekirdeğinde bir örnek olacak şekilde, dolayısıyla da yük ve görevleri örneklerin arasında dağıtır.
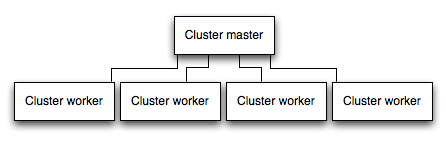
ÖNEMLİ: Uygulama örnekleri ayrı süreçler olarak koştuklarından, aynı hafıza alanını paylaşmıyorlar. Yani, objeler her uygulama örneği için lokaldir. Bu nedenle, uygulama kodunda durumu (state) koruyamazsınız. Ancak, durum ve oturum ile ilgili veriyi depolamak için Redis gibi bir in-memory veri deposu kullanabilirsiniz. Bu uyarı esases, kümeleme birden fazla süreç ya da birden fazla fiziksel sunucularla olsun, tüm yatay ölçekleme biçimleri için geçerlidir.
Kümelenmiş uygulamalarda, çalışan süreçleri (worker process) bireysel olarak geri kalan süreçleri etkilemeden çökebilirler. Performans avantajlarından ayrı olarak, arıza izolasyonu, bir uygulama süreçleri kümesini çalıştırmanın başka bir nedenidir. Ne zaman bir çalışan süreci çökerse, olayı loglayıp ve cluster.fork() kullanarak yeni bir süreç yaratmayı unutmayın.
Node’un cluster modülünü kullan
Kümeleme, Node’un cluster modülü sayesinde mümkün hale gelmiştir. Bu, bir ana sürecin çalışan süreçleri üretmesini ve gelen bağlantıları çalışanlar arasında dağıtmasını sağlar. Ancak, direkt olarak bu modülü kullanmak yerine, bu işi otomatik olarak yapan birçok araçtan birini kullanmak çok daha iyi; örneğin node-pm ya da cluster-service.
StrongLoop süreç yöneticisi kullan
Uygulamanızı StrongLoop süreç yöneticisine dağıtırsanız, uygulamanızın kodunu değiştirmeden kümelemenin avantajından yararlanabilirsiniz.
StrongLoop süreç yöneticisi bir uygulamayı koştuğunda, sistemdeki CPU çekirdeği sayısına eşit sayıda çalışanı olan bir kümede otomatik olarak çalıştırır. Uygulamayı durdurmadan slc komut satırı aracını kullanarak kümedeki çalışan süreçlerin sayısını manuel olarak değiştirebilirsiniz.
Örnek olarak, uygulamanızı prod.foo.com’a dağıttığınızı ve StrongLoop süreç yöneticisinin de port 8701’de (varsayılan) dinlediğini varsayarsak, slc kullanarak kümenin büyüklüğünü sekize ayarlamak için:
$ slc ctl -C http://prod.foo.com:8701 set-size my-app 8
StrongLoop ile kümeleme hakkında daha fazla bilgi için, StrongLoop dökümantasyonuna bakınız: Kümeleme
PM2 kullan
Uygulamanızı PM2 ile dağıtırsanız, uygulamanızın kodunu değiştirmeden kümelemenin avantajından yararlanabilirsiniz. İlk önce uygulamanızın durumsuz (stateless) olmasını sağlamalısınız, yani süreçte herhangi bir lokal veri saklanmamalıdır (oturum, websocket vb. bağlantılar).
PM2 ile bir uygulama koşulduğunda, seçtiğiniz örnek sayısıyla beraber bir kümede çalıştırmak için küme modunu etkinleştirebilirsiniz, makinedeki mevcut CPU sayısıyla eşleştirilmesi gibi. Uygulamayı durdurmadan pm2 komut satırı aracını kullanarak kümedeki süreç sayısını elle değiştirebilirsiniz.
Küme modunu etkinleştirmek için, uygulamanızı bu şekilde başlatın:
# 4 çalışan süreç başlat
$ pm2 start app.js -i 4
# Mevcut CPU sayısını otomatik olarak tespit et ve o sayı kadar çalışan süreç başlat
$ pm2 start app.js -i max
Bu aynı zamanda exec_mode değerini cluster ve instances değerini de başlangıç çalışan sayısı olarak ayarlayarak bir PM2 süreç dosyası (ecosystem.config.js ya da benzeri) içinde de yapılandırılabilir
Koşmaya başladıktan sonra, app isminde belirli bir uygulama aşağıdaki gibi ölçeklenebilir:
# 3 tane daha çalışan ekle
$ pm2 scale app +3
# Belirli bir çalışan sayınıa ölçeklendir
$ pm2 scale app 2
PM2 ile kümeleme hakkında daha fazla bilgi için PM3 dökümantasyonuna bakınız: Cluster Mode
İstek sonuçlarını önbelleğe al
Üretim ortamında performansı artırmak için bir başka strateji, isteklerin sonucunu önbelleğe almaktır, böylece uygulamanız aynı isteği tekrar tekrar sunmak için işlemi tekrarlamaz.
Uygulamanızın hızını ve performansını büyük ölçüde iyileştirmek için Varnish veya Nginx (ayrıca bakınız Nginx Caching) gibi bir önbelleğe alma sunucusu kullanın.
Bir yük dengeleyicisi kullan
Bir uygulama ne kadar optimize edilmiş olursa olsun, tek bir örnek yalnızca sınırlı miktarda yük ve trafiği kaldırabilir. Bir uygulamayı ölçeklendirmenin bir yolu, birden çok örneğini çalıştırmak ve trafiği bir yük dengeleyici aracılığıyla dağıtmaktır. Bir yük dengeleyici kurmak, uygulamanızın performansını ve hızını artırabilir ve tek bir örnekle mümkün olandan daha fazla ölçeklenmesini sağlayabilir.
Yük dengeleyici, genellikle birden çok uygulama örneği ve sunucusuna gelen ve giden trafiği düzenleyen bir ters proxy’dir. Nginx veya HAProxy kullanarak uygulamanız için bir yük dengeleyiciyi kolayca kurabilirsiniz.
Yük dengeleyici kullanırken, belirli bir oturum kimliğiyle ilişkili isteklerin, onları oluşturan sürece bağlanmasını sağlamanız gerekebilir. Bu, oturum yakınlığı (session affinity), veya yapışkan oturumlar (sticky sessions) olarak bilinir, ve oturum verileri için Redis gibi bir veri deposunun kullanılması için yukarıdaki öneri ile ele alınabilir (uygulamanıza bağlı olarak). Tartışma için bakınız Birden çok node kullanmak.
Ters proxy kullan
Bir ters proxy, bir web uygulamasının önünde oturur ve istekleri uygulamaya yeniden yönlendirmenin yanı sıra istekler üzerinde destekleyici işlemler gerçekleştirir. Diğer şeylerin yanı sıra hata sayfalarını, sıkıştırmayı, önbelleğe almayı, dosyaları sunmayı ve yük dengelemeyi de işleyebilir.
Handing over tasks that do not require knowledge of application state to a reverse proxy frees up Express to perform specialized application tasks. For this reason, it is recommended to run Express behind a reverse proxy like Nginx or HAProxy in production.
Uygulama durumu (state) bilgisi gerektirmeyen görevleri bir ters proxy’ye devretmek, özel uygulama görevlerini gerçekleştirmek için Express’i serbest bırakır. Bu nedenle, üretim ortamında Express’i Nginx veya HAProxy gibi bir ters proxy’nin arkasında koşmak tavsiye edilir.