Best Practices: Leistung und Zuverlässigkeit
Dieser Artikel befasst sich mit der Leistungsfähigkeit und der Zuverlässigkeit der besten Verfahren für Express-Anwendungen, die in der Produktion eingesetzt werden.
Dieses Thema fällt eindeutig in die “Devops”-Welt, die sowohl traditionelle Entwicklung als auch Operationen umfasst. Dementsprechend sind die Informationen in zwei Teile aufgeteilt:
- Dinge in Ihrem Code zu tun (dev part):
- Dinge zu tun in Ihrer Umgebung / in Ihrer Umgebung (der Ops-Teil):
Dinge in deinem Code zu tun
Hier sind einige Dinge, die Sie in Ihrem Code tun können, um die Leistung Ihrer Anwendung zu verbessern:
Gzip Komprimierung verwenden
Gzip-Komprimierung kann die Reaktionskörper erheblich verringern und damit die Geschwindigkeit einer Web-App erhöhen. Benutzen Sie die compression Middleware für gzip Komprimierung in Ihrer Express-App. Zum Beispiel:
const compression = require('compression');const express = require('express');const app = express();
app.use(compression());Für eine stark frequentierte Website in der Produktion, der beste Weg zur Komprimierung ist die Implementierung auf umgekehrter Proxyebene (siehe Reverse Proxy) . In diesem Fall brauchen Sie keine Komprimierungsmittelware. Details zum Aktivieren der gzip-Komprimierung in Nginx finden Sie unter Module ngx_http_gzip_module in der Nginx-Dokumentation.
Keine synchronen Funktionen verwenden
Synchronische Funktionen und Methoden binden den Ausführungsprozess bis sie zurückkehren. Ein einzelner Aufruf einer synchronen Funktion kann in ein paar Mikrosekunden oder Millisekunden zurückgegeben werden auf Websites mit hohem Traffic jedoch tragen diese Anrufe dazu bei, die Performance der App zu reduzieren. Vermeiden Sie ihren Einsatz in der Produktion.
Obwohl Node und viele Module synchrone und asynchrone Versionen ihrer Funktionen liefern, verwenden Sie immer die asynchrone Version in der Produktion. Die einzige Zeit, in der eine synchrone Funktion gerechtfertigt werden kann, ist beim ersten Start.
Du kannst das --trace-sync-io Kommandozeilen-Flag verwenden, um eine Warnung und einen Stack-Trace zu drucken, wann immer deine Anwendung eine synchrone API verwendet. Natürlich möchten Sie dies nicht in der Produktion verwenden, sondern vielmehr sicherstellen, dass Ihr Code produktionsbereit ist. Weitere Informationen finden Sie in der Knoten Kommandozeilenoptionen Dokumentation .
Logging korrekt
Im Allgemeinen gibt es zwei Gründe für die Protokollierung aus Ihrer App: Für das Debuggen und für die Protokollierung von App-Aktivitäten (im Wesentlichen alles andere). Die Verwendung von console.log() oder console.error() zum Drucken von Logmeldungen an das Terminal ist gängige Praxis in der Entwicklung. Aber diese Funktionen sind synchronisiert, wenn das Ziel ein Terminal oder eine Datei ist so dass sie nicht für die Produktion geeignet sind, es sei denn, Sie rollen die Ausgabe zu einem anderen Programm.
Zum Debuggen
Wenn du zum Debuggen loggst, benutze anstelle von console.log() ein spezielles Debugging-Modul wie debug. Dieses Modul ermöglicht es Ihnen, die DEBUG Umgebungsvariable zu verwenden, um zu kontrollieren, welche Debug-Meldungen an console.error() gesendet werden, falls vorhanden. Um deine App rein asynchron zu halten, solltest du trotzdem console.error() zu einem anderen Programm weiterleiten. Aber dann bist du nicht wirklich in der Produktion zu debuggen, oder?
Für App-Aktivitäten
Wenn Sie App-Aktivitäten protokollieren (zum Beispiel Traffic oder API-Aufrufe), anstatt „Konsole“. og()`, verwende eine Logging-Bibliothek wie Pino, die schnellste und effizienteste verfügbare Option.
Ausnahmen richtig handhaben
Knoten-Apps stürzen ab, wenn sie auf eine nicht gefangene Ausnahme stoßen. Wenn Sie Ausnahmen nicht bearbeiten und entsprechende Maßnahmen ergreifen, wird Ihre Express-App zum Absturz bringen und offline gehen. Wenn du dem Rat folgst Stelle sicher, dass deine App automatisch neu startet unten, dann wird deine App von einem Absturz erholt. Glücklicherweise haben Express-Apps in der Regel eine kurze Startzeit. Nichtsdestotrotz wollen Sie einen Absturz vermeiden, und dazu müssen Sie die Ausnahmen ordentlich behandeln.
Um sicherzustellen, dass Sie mit allen Ausnahmen umgehen, verwenden Sie folgende Techniken:
Bevor Sie in diese Themen eintauchen, sollten Sie ein grundlegendes Verständnis von Node/Express-Fehlerbehandlung haben: Verwendung von Fehler-First Callbacks und Verbreitung von Fehlern in Middleware. Knoten verwendet eine “error-first callback”-Konvention um Fehler aus asynchronen Funktionen zurückzugeben, wobei der erste Parameter der Callback-Funktion das Fehlerobjekt ist, gefolgt von Ergebnisdaten in folgenden Parametern. Um keinen Fehler anzugeben, übergeben Sie Null als ersten Parameter. Die Callback-Funktion muss entsprechend der ersten Callback-Konvention folgen, um den Fehler sinnvoll zu bearbeiten. Und in Express ist es am besten, die next() Funktion zu nutzen, um Fehler über die Middleware-Kette zu verbreiten.
Für mehr über die Grundlagen der Fehlerbehandlung, siehe:
Versuchsfang verwenden
Try-catch ist eine JavaScript-Sprachkonstruktion, die Sie verwenden können, um Ausnahmen im synchronen Code zu fangen. Verwenden Sie zum Beispiel den versuchen Catch, um JSON-Parsing-Fehler wie unten gezeigt zu behandeln.
Hier ist ein Beispiel für die Verwendung von “try-catch”, um eine mögliche Prozessabsturzausnahme zu bewältigen. Diese Middleware-Funktion akzeptiert einen Abfragefeldparameter namens “params”, das ein JSON-Objekt ist.
app.get('/search', (req, res) => { // Simulating async operation setImmediate(() => { const jsonStr = req.query.params; try { const jsonObj = JSON.parse(jsonStr); res.send('Success'); } catch (e) { res.status(400).send('Invalid JSON string'); } });});Der Versuch funktioniert jedoch nur für synchrone Code. Da die Knotenplattform primär asynchron ist (insbesondere in einer Produktionsumgebung), wird der Versuch nicht viele Ausnahmen fangen.
Versprechen verwenden
Wenn ein Fehler in einer async Funktion ausgelöst wird oder ein abgelehntes Versprechen in einer async Funktion erwartet wird, diese Fehler werden an den Fehlerhandler übergeben, als ob next(err) aufgerufen würde
app.get('/', async (req, res, next) => { const data = await userData(); // If this promise fails, it will automatically call `next(err)` to handle the error.
res.send(data);});
app.use((err, req, res, next) => { res.status(err.status ?? 500).send({ error: err.message });});Außerdem können Sie asynchrone Funktionen für Ihre Middleware verwenden und der Router verarbeitet Fehler, wenn das Versprechen fehlschlägt, zum Beispiel:
app.use(async (req, res, next) => { req.locals.user = await getUser(req);
next(); // This will be called if the promise does not throw an error.});Best Practices ist es, Fehler so nah wie möglich an der Website zu behandeln. So während dies jetzt im Router behandelt wird, ist es am besten, den Fehler in der Middleware zu fangen und ihn zu bearbeiten, ohne sich auf eine separate Middleware zu verlassen.
Was nicht zu tun
Eine Sache, die du nicht tun solltest ist, auf das uncaptException Event zu hören emittiert, wenn eine Ausnahme den ganzen Weg zurück zur Ereignis-Schleife weht. Das Hinzufügen eines Ereignis-Listeners für uncaughtException ändert das Standardverhalten des Prozesses, der auf eine Ausnahme stößt; wird der Prozess trotz der Ausnahme weiterhin laufen. Dies könnte nach einer guten Möglichkeit klingen, um zu verhindern, dass Ihre App abstürzt, aber die Anwendung nach einer nicht gefangenen Ausnahme weiterhin zu laufen ist eine gefährliche Praxis und wird nicht empfohlen, weil der Zustand des Prozesses unzuverlässig und unberechenbar wird.
Zusätzlich wird die Verwendung von uncaughtException offiziell als [crude]anerkannt (https://nodejs.org/api/process#process_event_uncaughtexception). Also ist das Hören auf uncaughtException eine schlechte Idee. Aus diesem Grund empfehlen wir Dinge wie mehrere Prozesse und Supervisoren: Absturz und Neustart sind oft der zuverlässigste Weg, um einen Fehler zu beheben.
Wir empfehlen auch nicht [domains]zu verwenden (https://nodejs.org/api/domain). Es löst das Problem im Allgemeinen nicht und ist ein veraltetes Modul.
Dinge zu tun in Ihrer Umgebung / Einrichtung
Hier sind einige Dinge, die Sie in Ihrer Systemumgebung tun können, um die Leistung Ihrer App zu verbessern:
- Setze NODE_ENV auf “Produktion”
- Stelle sicher, dass deine App automatisch neu startet
- Starte deine App in einem Cluster
- Cache-Anfrageergebnisse
- Lastausgleich verwenden
- Reverse Proxy verwenden
Knoten_ENV auf “Produktion” setzen
Die NODE_ENV Umgebungsvariable spezifiziert die Umgebung, in der eine Anwendung ausgeführt wird (normalerweise Entwicklung oder Produktion). Eines der einfachsten Dinge, die Sie tun können, um die Leistung zu verbessern, ist, NODE_ENV auf production zu setzen.
Setze NODE_ENV auf “production” makes Express:
- Cache-Ansichtsvorlagen.
- Cache-CSS-Dateien, die aus CSS-Erweiterungen generiert wurden.
- Weniger ausführliche Fehlermeldungen generieren.
Tests deuten an, dass dies die Leistung der App um einen Faktor von drei verbessern kann!
Wenn Sie umweltspezifischen Code schreiben müssen, können Sie den Wert von NODE_ENV mit process.env.NODE_ENV überprüfen. Beachten Sie, dass die Überprüfung des Wertes einer Umgebungsvariable eine Leistungsstrafe verursacht und daher sparsam durchgeführt werden sollte.
In der Entwicklung setzst du in der Regel Umgebungsvariablen in deiner interaktiven Shell ein, indem du export oder deine .bash_profile Datei verwendest. Aber im Allgemeinen sollten Sie das nicht auf einem Produktionsserver tun; stattdessen sollten Sie das Init-System Ihres Betriebssystems (System) verwenden. Der nächste Abschnitt enthält weitere Details zur Verwendung Ihres Init-Systems im Allgemeinen aber das Setzen von NODE_ENV ist so wichtig für die Leistung (und einfach zu tun), dass es hier hervorgehoben wird.
Mit dem System verwenden Sie die Environment Direktive in Ihrer Einheitendatei. Zum Beispiel:
Environment=NODE_ENV=productionWeitere Informationen finden Sie unter Umgebungsvariablen in systemd Units.
Stellen Sie sicher, dass Ihre App automatisch neu gestartet wird
In der Produktion wollen Sie nicht, dass Ihre Bewerbung offline ist. Dies bedeutet, dass Sie sicherstellen müssen, dass es sowohl neu gestartet wird, wenn die App abstürzt als auch wenn der Server selbst abstürzt. Obwohl Sie hoffen, dass keines dieser Ereignisse eintritt, müssen Sie realistischerweise beide Eventualitäten berücksichtigen von:
- Verwendung eines Prozess-Managers, um die App (und den Knoten) neu zu starten, wenn sie abstürzt.
- Verwendung des von Ihrem Betriebssystem zur Verfügung gestellten Init-Systems, um den Prozessmanager beim Absturz des Betriebssystems neu zu starten. Es ist auch möglich, das Init-System ohne Prozessmanager zu verwenden.
Knotenapplikationen stürzen ab, wenn sie eine nicht gefangene Ausnahme erleben. Das Wichtigste, was Sie tun müssen, ist, sicherzustellen, dass Ihre App gut getestet ist und alle Ausnahmen handhabt (siehe Ausnahmen ordnungsgemäß behandeln für Details). Aber als Fail-Safe setzen Sie einen Mechanismus, um sicherzustellen, dass wenn und wenn Ihre App abstürzt, automatisch neu gestartet wird.
Prozessmanager verwenden
In der Entwicklung hast du deine App einfach von der Kommandozeile aus mit node server.js oder etwas Ähnlichem gestartet. Aber dies in der Produktion zu tun, ist ein Rezept für eine Katastrophe. Wenn die App abstürzt, wird sie offline sein, bis Sie sie neu starten. Um sicherzustellen, dass Ihre App neu gestartet wird, wenn sie abstürzt, verwenden Sie einen Prozessmanager. Ein Prozessmanager ist ein “Container” für Anwendungen, die den Einsatz erleichtern, eine hohe Verfügbarkeit bieten und Ihnen die Verwaltung der Anwendung zur Laufzeit ermöglichen.
Zusätzlich zum Neustart Ihrer App bei einem Absturz kann ein Prozessmanager Sie aktivieren:
- Gewinnen Sie Einblicke in Laufzeitleistung und Ressourcenverbrauch.
- Ändern Sie die Einstellungen dynamisch, um die Leistung zu verbessern.
- Steuerung Clustering (pm2).
Historisch war es beliebt, einen Node.js Prozessmanager wie PM2 zu verwenden. Lesen Sie deren Dokumentation, wenn Sie dies tun möchten. Wir empfehlen jedoch, Ihr Init-System für das Prozessmanagement zu verwenden.
Init-System verwenden
Die nächste Ebene der Zuverlässigkeit besteht darin, sicherzustellen, dass Ihre App beim Neustart des Servers neu gestartet wird. Systeme können aus verschiedenen Gründen immer noch heruntergehen. Um sicherzustellen, dass Ihre App neu gestartet wird, wenn der Server abstürzt, verwenden Sie das Init-System, das in Ihr Betriebssystem integriert wurde. Das heute verwendete Hauptinitsystem ist systemd.
Es gibt zwei Möglichkeiten, Init-Systeme mit Ihrer Express-App zu verwenden:
- Führen Sie Ihre App in einem Prozessmanager aus und installieren Sie den Prozessmanager als Service mit dem Init-System. Der Prozessmanager startet Ihre App neu, wenn die App abstürzt, und das Init-System startet den Prozessmanager beim Neustart des Betriebssystems neu. Dies ist der empfohlene Ansatz.
- Führen Sie Ihre App (und Ihren Knoten) direkt mit dem Init-System aus. Das ist etwas einfacher, aber Sie haben nicht die zusätzlichen Vorteile eines Prozessmanagers.
Systemd
Systemd ist ein Linux System und Service Manager. Die meisten großen Linux-Distributionen haben System als Standard-Init-System übernommen.
Eine Systemd-Service-Konfigurationsdatei heißt unit file, mit einem Dateinamen endet in .service. Hier ist eine Beispiel-Einheitsdatei, um eine Knoten-App direkt zu verwalten. Ersetzen Sie die Werte in <angle brackets> für Ihr System und App:
[Unit]Description=<Awesome Express App>
[Service]Type=simpleExecStart=/usr/local/bin/node </projects/myapp/index.js>WorkingDirectory=</projects/myapp>
User=nobodyGroup=nogroup
Environment=NODE_ENV=production
LimitNOFILE=infinity
LimitCORE=infinity
StandardInput=nullStandardOutput=syslogStandardError=syslogRestart=always
[Install]WantedBy=multi-user.targetWeitere Informationen zum System finden Sie unter systemd reference (man page).
Starte deine App in einem Cluster
In einem Multi-Core-System können Sie die Leistung einer Knoten-App um ein Vielfaches erhöhen, indem Sie einen Cluster von Prozessen starten. Ein Cluster führt mehrere Instanzen der App aus, idealerweise eine Instanz auf jedem CPU-Core, wodurch die Last und Aufgaben auf die Instanzen verteilt werden.
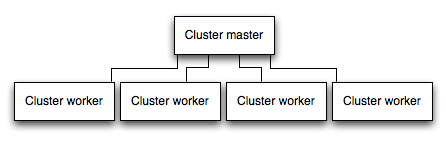
WICHTIG: Da die App-Instanzen als separate Prozesse laufen, teilen sie nicht den gleichen Speicherplatz. Das heißt, Objekte sind lokal für jede Instanz der App. Daher können Sie den Status im Anwendungscode nicht beibehalten. Du kannst jedoch einen Speicherdatenspeicher wie Redis verwenden, um Sitzungsdaten und -status zu speichern. Dieser Vorbehalt bezieht sich im Wesentlichen auf alle Formen der horizontalen Skalierung, sei es beim Clustering mit mehreren Prozessen oder mehreren physischen Servern.
In geclusterten Apps können Worker-Prozesse individuell abstürzen, ohne den Rest der Prozesse zu beeinträchtigen. Abgesehen von den Leistungsvorteilen ist die Fehlerisolierung ein weiterer Grund, einen Cluster von App-Prozessen auszuführen. Immer wenn ein Worker-Prozess abstürzt, vergewissern Sie sich, das Ereignis zu protokollieren und einen neuen Prozess mit cluster.fork() zu erzeugen.
Cluster-Modul des Knotens
Clustering wird mit Knotens Cluster-Modul ermöglicht. Dies ermöglicht es einem Master-Prozess, Worker-Prozesse zu generieren und eingehende Verbindungen unter den Arbeitern zu verteilen.
PM2 verwenden
Wenn Sie Ihre Anwendung mit PM2 bereitstellen, können Sie die Vorteile des Clustering without out Ändern Ihres Anwendungscodes nutzen. Du solltest sicherstellen, dass deine Anwendung zustandslos ist zuerst , was bedeutet, dass keine lokalen Daten im Prozess gespeichert werden (wie Sessions, Websocket-Verbindungen und dergleichen).
Wenn du eine Anwendung mit PM2 ausführst, kannst du den Cluster-Modus aktivieren, um ihn in einem Cluster mit einer Anzahl von Instanzen deiner Wahl auszuführen zum Beispiel die übereinstimmende Anzahl der verfügbaren CPUs. Du kannst die Anzahl der Prozesse im Cluster manuell mit dem Kommandozeilenwerkzeug pm2 ändern, ohne die App zu stoppen.
Um den Cluster-Modus zu aktivieren, starten Sie Ihre Anwendung so:
$ pm2 start npm --name my-app -i 4 -- start
$ pm2 start npm --name my-app -i max -- startDies kann auch innerhalb einer PM2-Prozessdatei konfiguriert werden (ecosystem.config. s oder ähnlich) indem exec_mode auf cluster und instances auf die Anzahl der zu startenden Arbeiter gesetzt wird.
Nach dem Ausführen kann die Anwendung so skaliert werden:
$ pm2 scale my-app +3
$ pm2 scale my-app 2Weitere Informationen zum Clustering mit PM2 finden Sie unter Cluster Mode in der PM2-Dokumentation.
Cache-Abfrageergebnisse
Eine weitere Strategie zur Verbesserung der Leistung in der Produktion ist das Cache-Ergebnis von Anfragen so dass Ihre App die Operation nicht wiederholt, um dieselbe Anfrage wiederholt zu bedienen.
Benutze einen Caching-Server wie Varnish oder Nginx (siehe auch Nginx Caching) um die Geschwindigkeit und Leistung deiner App deutlich zu verbessern.
Lastausgleich verwenden
Egal wie optimiert eine App ist, eine einzelne Instanz kann nur eine begrenzte Menge an Last und Traffic verwalten. Eine Möglichkeit, eine App zu skalieren, besteht darin, mehrere Instanzen davon auszuführen und den Traffic über einen Lastausgleicher zu verteilen. Das Einrichten eines Lastausgleichs kann die Leistung und Geschwindigkeit Ihrer App verbessern und es ermöglichen, mehr zu skalieren, als mit einer einzigen Instanz möglich ist.
Ein Loadbalancer ist in der Regel ein Reverse-Proxy, der den Datenverkehr zu und von mehreren Anwendungsinstanzen und Servern regelt. Mit Nginx oder HAProxy können Sie ganz einfach einen Lastausgleich für Ihre App einrichten.
Bei Loadbalancing müssen Sie eventuell sicherstellen, dass Anforderungen, die mit einer bestimmten Session-ID in Verbindung stehen, mit dem Prozess verbunden sind, der sie verursacht hat. Dies ist session, oder sticky sessions, bekannt und kann durch den oben genannten Vorschlag angesprochen werden, um einen Datenspeicher wie Redis für Sitzungsdaten (je nach Anwendung) zu verwenden. Für eine Diskussion siehe Mehrere Knoten verwenden.
Reverse-Proxy verwenden
Ein Reverse Proxy sitzt vor einer Web-App und führt unterstützende Operationen auf den Anfragen aus, abgesehen von der Weiterleitung von Anfragen an die App. Es kann Fehlerseiten, Komprimierung, Caching, Servieren von Dateien und laden Balancing unter anderem.
Die Übergabe von Aufgaben, die keine Kenntnisse des Anwendungszustands an einen Reverse Proxy erfordern, gibt Express frei, spezielle Anwendungsaufgaben durchzuführen. Aus diesem Grund wird empfohlen, Express in der Produktion hinter einem umgekehrten Proxy wie Nginx oder HAProxy auszuführen.