Migliori pratiche di produzione: prestazioni e affidabilità
Questo articolo discute le migliori pratiche di performance e affidabilità per le applicazioni Express distribuite alla produzione.
Questo argomento rientra chiaramente nel mondo dei “devops”, che abbraccia sia lo sviluppo tradizionale che le operazioni. Di conseguenza, le informazioni sono suddivise in due parti:
- Cose da fare nel tuo codice (la parte dev):
- Cose da fare nel tuo ambiente / configurazione (la parte ops):
Cose da fare nel tuo codice
Ecco alcune cose che puoi fare nel tuo codice per migliorare le prestazioni della tua applicazione:
- Usa compressione gzip
- Non utilizzare le funzioni sincrone
- Effettua la registrazione corretta
- Maneggiare correttamente le eccezioni
Usa compressione gzip
La compressione di Gzip può ridurre notevolmente la dimensione del corpo della risposta e quindi aumentare la velocità di una web app. Usa il middleware compression per la compressione gzip nella tua app Express. Per esempio:
const compression = require('compression');const express = require('express');const app = express();
app.use(compression());Per un sito web ad alto traffico in produzione, il modo migliore per mettere in atto la compressione è implementarla a un livello di proxy inverso (vedere Usa un proxy inverso). In tal caso, non è necessario utilizzare middleware di compressione. Per maggiori dettagli sull’attivazione della compressione gzip in Nginx, vedere Modulo ngx_http_gzip_module nella documentazione Nginx.
Non utilizzare funzioni sincrone
Le funzioni e i metodi sincroni legano il processo di esecuzione fino al loro ritorno. Una singola chiamata ad una funzione sincrona potrebbe tornare in pochi microsecondi o millisecondi, tuttavia nei siti web ad alto traffico, queste chiamate si sommano e riducono le prestazioni dell’app. Evitare il loro uso in produzione.
Sebbene Node e molti moduli forniscano versioni sincrone e asincrone delle loro funzioni, utilizzare sempre la versione asincrona in produzione. L’unico momento in cui una funzione sincrona può essere giustificata è all’avvio iniziale.
Puoi usare il flag da riga di comando --trace-sync-io per stampare un avviso e uno stack trace ogni volta che la tua applicazione utilizza un’API sincrona. Naturalmente, non si desidera utilizzare questo in produzione, ma piuttosto per garantire che il codice è pronto per la produzione. Vedi la documentazione delle opzioni a riga di comando del nodo per maggiori informazioni.
Effettuare la registrazione correttamente
In generale, ci sono due motivi per la registrazione dalla tua app: Per il debug e per la registrazione delle attività delle app (essenzialmente, tutto il resto). Usare console.log() o console.error() per stampare i messaggi di log sul terminale è una pratica comune nello sviluppo. Ma queste funzioni sono sincrone quando la destinazione è un terminale o un file, in modo che non siano adatti per la produzione, a meno che non convogliate l’uscita ad un altro programma.
Per il debug
Se stai registrando a fini di debug, invece di usare console.log(), usa uno speciale modulo di debug come debug. Questo modulo consente di utilizzare la variabile di ambiente DEBUG per controllare quali messaggi di debug vengono inviati a console.error(), se presenti. Per mantenere la tua app puramente asincrona, dovresti ancora reindirizzare console.error() ad un altro programma. Ma allora, non stai davvero andando a debug nella produzione, vero?
Per attività app
Se stai registrando le attività delle app (ad esempio, tracciando traffico o chiamate API), invece di usare console. og(), usa una libreria di registrazione come Pino, che è l’opzione più veloce ed efficiente disponibile.
Gestisci correttamente le eccezioni
Le app del nodo si bloccano quando incontrano un’eccezione non catturata. Non gestire le eccezioni e intraprendere azioni appropriate renderà il tuo crash di app Express e andare offline. Se segui i consigli in Assicurati che la tua app riavvii automaticamente qui sotto, allora la tua app recupererà da un crash. Fortunatamente, le applicazioni Express in genere hanno un breve tempo di avvio. Tuttavia, si desidera evitare di schiantarsi in primo luogo, e per farlo, è necessario gestire le eccezioni correttamente.
Per garantire la gestione di tutte le eccezioni, utilizzare le seguenti tecniche:
Prima di immergersi in questi argomenti, si dovrebbe avere una comprensione di base della gestione degli errori Node/Express: utilizzando error-first callback e gli errori di propagazione in middleware. Il nodo utilizza una convenzione “error-first callback” per restituire gli errori dalle funzioni asincrone, dove il primo parametro della funzione callback è l’oggetto errore, seguito da dati di risultato in parametri successivi. Per indicare nessun errore, passare null come primo parametro. La funzione di callback deve seguire in modo corrispondente la convenzione di callback errore-first callback per gestire in modo significativo l’errore. E in Express, la migliore pratica è quella di utilizzare la funzione next() per propagare gli errori attraverso la catena middleware.
Per maggiori informazioni sui fondamenti della gestione degli errori, consultare:
Usa try-catch
Try-catch è una struttura in linguaggio JavaScript che puoi usare per catturare le eccezioni in codice sincrono. Usa try-catch, per esempio, per gestire gli errori di analisi JSON come mostrato di seguito.
Ecco un esempio di utilizzo di try-catch per gestire una potenziale eccezione di processo-crashing. Questa funzione middleware accetta un parametro del campo di query denominato “params” che è un oggetto JSON.
app.get('/search', (req, res) => { // Simulating async operation setImmediate(() => { const jsonStr = req.query.params; try { const jsonObj = JSON.parse(jsonStr); res.send('Success'); } catch (e) { res.status(400).send('Invalid JSON string'); } });});Tuttavia, try-catch funziona solo per il codice sincrono. Poiché la piattaforma Nodo è principalmente asincrona (in particolare in un ambiente di produzione), il try-catch non prenderà molte eccezioni.
Usa promesse
Quando un errore viene lanciato in una funzione async o una promessa rifiutata è attesa all’interno di una funzione async, questi errori verranno passati al gestore degli errori come se chiamasse next(err)
app.get('/', async (req, res, next) => { const data = await userData(); // If this promise fails, it will automatically call `next(err)` to handle the error.
res.send(data);});
app.use((err, req, res, next) => { res.status(err.status ?? 500).send({ error: err.message });});Inoltre, è possibile utilizzare funzioni asincrone per il vostro middleware, e il router gestirà gli errori se la promessa fallisce, per esempio:
app.use(async (req, res, next) => { req.locals.user = await getUser(req);
next(); // This will be called if the promise does not throw an error.});La migliore pratica è quella di gestire gli errori il più vicino possibile al sito. Quindi, mentre questo è ora gestito nel router, è meglio catturare l’errore nel middleware e gestirlo senza fare affidamento su middleware di gestione degli errori separati.
Cosa non fare
Una cosa che dovresti non fare è ascoltare per l’evento uncaughtException, emessa quando una bolla di eccezione ritorna fino al ciclo evento. L’aggiunta di un ascoltatore di eventi per uncaughtException cambierà il comportamento predefinito del processo che sta incontrando un’eccezione; il processo continuerà a funzionare nonostante l’eccezione. Questo potrebbe sembrare un buon modo per impedire che la tua app si blocchi, ma continuare ad eseguire l’app dopo un’eccezione non catturata è una pratica pericolosa e non è raccomandato, perché lo stato del processo diventa inaffidabile e imprevedibile.
Inoltre, l’utilizzo di uncaughtException è ufficialmente riconosciuto come crude. Quindi ascoltare uncaughtException è solo una cattiva idea. Questo è il motivo per cui consigliamo cose come più processi e supervisori: crash e riavvio è spesso il modo più affidabile per recuperare da un errore.
Inoltre non consigliamo di utilizzare domains. Generalmente non risolve il problema ed è un modulo deprecato.
Cose da fare nel tuo ambiente / configurazione
Ecco alcune cose che puoi fare nel tuo ambiente di sistema per migliorare le prestazioni della tua app:
- Imposta NODE_ENV a “production”
- Assicurati che l’app si riavvii automaticamente
- Esegui la tua app in un cluster
- Cache request results
- Usa un balancer
- Usa un proxy inverso
Imposta NODE_ENV a “produzione”
La variabile d’ ambiente NODE_ENV specifica l’ ambiente in cui un’ applicazione è in esecuzione (solitamente, sviluppo o produzione). Una delle cose più semplici che puoi fare per migliorare le prestazioni è impostare NODE_ENV a produzione.
Impostando NODE_ENV a “production” makes Express:
- Modelli visualizzazione della cache.
- File CSS della cache generati dalle estensioni CSS.
- Genera messaggi di errore meno dettagliati.
Tests indicate che solo facendo questo può migliorare le prestazioni dell’app di un fattore di tre!
Se è necessario scrivere un codice specifico per l’ambiente, è possibile controllare il valore di NODE_ENV con process.env.NODE_ENV. Essere consapevoli che il controllo del valore di qualsiasi variabile ambientale comporta una penalità di prestazione, e quindi dovrebbe essere fatto con parsimonia.
In fase di sviluppo, in genere imposterai le variabili di ambiente nella tua shell interattiva, ad esempio usando export o il tuo file .bash_profile. Ma in generale, non dovresti farlo su un server di produzione; invece, usa il sistema di ingresso del tuo sistema operativo (systemd). La sezione successiva fornisce maggiori dettagli sull’utilizzo del sistema di init in generale, ma l’impostazione NODE_ENV è così importante per le prestazioni (e facile da fare), che è evidenziata qui.
Con il sistema, usa la direttiva Environment nel tuo file unitario. Per esempio:
Environment=NODE_ENV=productionPer ulteriori informazioni, vedere Uso delle variabili ambientali nelle unità systemd.
Assicurati che l’app si riavvii automaticamente
In produzione, non vuoi che la tua applicazione sia offline, mai. Ciò significa che è necessario assicurarsi che si riavvia sia se l’applicazione si blocca e se il server stesso si blocca. Anche se si spera che nessuno di questi eventi accada, realisticamente si deve rendere conto di entrambe le eventualità mediante:
- Utilizzando un gestore di processo per riavviare l’applicazione (e Node) quando si blocca.
- Utilizzando il sistema di init fornito dal sistema operativo per riavviare il gestore di processo quando il sistema operativo si blocca. È anche possibile utilizzare il sistema init senza un gestore di processo.
Le applicazioni del nodo si bloccano se incontrano un’eccezione non catturata. La cosa più importante che devi fare è assicurarsi che la tua app sia ben testata e gestisca tutte le eccezioni (vedi gestire le eccezioni correttamente per i dettagli). Ma come un fail-safe, mettere un meccanismo in atto per garantire che se e quando l’app si blocca, si riavvierà automaticamente.
Usa un gestore di processo
In fase di sviluppo, hai avviato la tua app semplicemente dalla riga di comando con node server.js o qualcosa di simile. Ma fare questo in produzione è una ricetta per il disastro. Se l’app si blocca, sarà offline fino al riavvio. Per garantire il riavvio dell’app in caso di crash usa un gestore di processo. Un process-manager è un “container” per le applicazioni che facilita l’implementazione, fornisce un’elevata disponibilità e consente di gestire l’applicazione durante il runtime.
Oltre a riavviare la tua app quando si blocca, un gestore di processo può permetterti di:
- Ottieni informazioni sulle prestazioni di runtime e sul consumo di risorse.
- Modifica le impostazioni dinamicamente per migliorare le prestazioni.
- Clustering di controllo (pm2).
Storicamente, era popolare usare un manager di processo Node.js come PM2. Vedere la loro documentazione se si desidera farlo. Tuttavia, si consiglia di utilizzare il sistema init per la gestione dei processi.
Usa un sistema init
Il livello successivo di affidabilità è quello di garantire che l’app si riavvia quando il server si riavvia. I sistemi possono ancora andare giù per una varietà di motivi. Per garantire che la tua app si riavvii in caso di crash del server, usa il sistema init integrato nel tuo sistema operativo. Il sistema di init principale oggi in uso è systemd.
Ci sono due modi per utilizzare i sistemi init con la tua app Express:
- Eseguire l’app in un gestore di processo e installare il gestore di processo come un servizio con il sistema init. Il gestore di processo riavvierà l’app quando l’app si blocca e il sistema init riavvierà il gestore di processo quando il sistema operativo riavvia. Questo è l’approccio raccomandato.
- Esegui la tua app (e Node) direttamente con il sistema init. Questo è un po ‘più semplice, ma non si ottengono i vantaggi aggiuntivi di utilizzare un manager di processo.
Systemd
Systemd è un sistema Linux e service manager. La maggior parte delle principali distribuzioni Linux hanno adottato systemd come sistema di init predefinito.
Un file di configurazione del servizio di sistema è chiamato unit file, con un nome di file che termina in .service. Ecco un file unità di esempio per gestire direttamente un’app Node. Sostituisci i valori racchiusi in <angle brackets> per il tuo sistema e l’app:
[Unit]Description=<Awesome Express App>
[Service]Type=simpleExecStart=/usr/local/bin/node </projects/myapp/index.js>WorkingDirectory=</projects/myapp>
User=nobodyGroup=nogroup
Environment=NODE_ENV=production
LimitNOFILE=infinity
LimitCORE=infinity
StandardInput=nullStandardOutput=syslogStandardError=syslogRestart=always
[Install]WantedBy=multi-user.targetPer ulteriori informazioni sul sistema, vedere systemd reference (man page).
Esegui la tua app in un cluster
In un sistema multi-core, è possibile aumentare le prestazioni di un’applicazione Nodo di molte volte lanciando un cluster di processi. Un cluster esegue più istanze dell’app, idealmente una istanza su ogni nucleo della CPU, distribuendo così il carico e le attività tra le istanze.
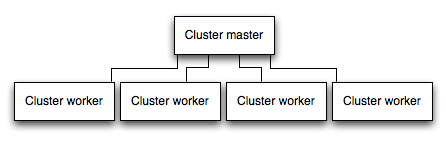
IMPORTANTE: Poiché le istanze dell’app vengono eseguite come processi separati, non condividono lo stesso spazio di memoria. Cioè, gli oggetti sono locali per ogni istanza dell’app. Pertanto, non è possibile mantenere lo stato nel codice dell’applicazione. Tuttavia, è possibile utilizzare un datastore in memoria come Redis per memorizzare i dati e lo stato relativi alla sessione. Questa avvertenza si applica essenzialmente a tutte le forme di ridimensionamento orizzontale, sia che si tratti di raggruppamento con più processi o più server fisici.
Nelle applicazioni raggruppate, i processi di lavoro possono bloccarsi individualmente senza influenzare il resto dei processi. Oltre ai vantaggi delle prestazioni, l’isolamento del guasto è un altro motivo per eseguire un cluster di processi app. Ogni volta che un processo di lavoro si blocca, assicurarsi sempre di registrare l’evento e generare un nuovo processo utilizzando cluster.fork().
Uso del modulo cluster Node
Il cluster è reso possibile con il modulo cluster di Node. Ciò consente a un processo master di generare processi di lavoro e distribuire le connessioni in entrata tra i lavoratori.
Uso PM2
Se distribuisci la tua applicazione con PM2, puoi approfittare del clustering without modificando il codice dell’applicazione. Dovresti prima assicurarti che la tua applicazione sia senza condizione il che significa che nessun dato locale viene memorizzato nel processo (ad esempio sessioni, connessioni websocket e simili).
Quando si esegue un’applicazione con PM2, è possibile abilitare la modalità cluster per eseguirla in un cluster con un certo numero di istanze a propria scelta, come il corrispondente numero di CPU disponibili sulla macchina. È possibile modificare manualmente il numero di processi nel cluster utilizzando lo strumento da riga di comando pm2 senza interrompere l’app.
Per abilitare la modalità cluster, avvia la tua applicazione così:
$ pm2 start npm --name my-app -i 4 -- start
$ pm2 start npm --name my-app -i max -- startQuesto può anche essere configurato all’interno di un file di processo PM2 (ecosystem.config. s o simile) impostando exec_mode su cluster e instances sul numero di lavoratori da avviare.
Una volta in esecuzione, l’applicazione può essere ridimensionata così:
$ pm2 scale my-app +3
$ pm2 scale my-app 2Per ulteriori informazioni sul clustering con PM2, vedere Modalità cluster nella documentazione PM2.
Risultati richiesta cache
Un’altra strategia per migliorare le prestazioni nella produzione è quella di nascondere il risultato delle richieste, in modo che l’app non ripeta l’operazione per servire la stessa richiesta ripetutamente.
Usa un server di cache come Varnish o Nginx (vedi anche Nginx Caching) per migliorare notevolmente la velocità e le prestazioni della tua app.
Usa un bilanciatore di carico
Non importa quanto sia ottimizzata un’app, una singola istanza può gestire solo una quantità limitata di carico e traffico. Un modo per scalare un’app è quello di eseguire più istanze di esso e distribuire il traffico tramite un balancer. La configurazione di un bilanciatore di carico può migliorare le prestazioni e la velocità della tua app e permetterle di scalare più di quanto sia possibile con una singola istanza.
Un bilanciatore di carico è di solito un proxy inverso che orchestra il traffico da e verso più istanze di applicazione e server. Puoi configurare facilmente un bilanciatore di carico per la tua app utilizzando Nginx o HAProxy.
Con il bilanciamento del carico, potrebbe essere necessario assicurarsi che le richieste associate a un particolare ID di sessione si connettano al processo che le ha originate. Questo è conosciuto come session affinity, o sticky sessions, e può essere affrontato dal suggerimento di cui sopra per utilizzare un archivio dati come Redis per i dati di sessione (a seconda della tua applicazione). Per una discussione, vedere Utilizzo di nodi multipli.
Usa un proxy inverso
Un proxy inverso si siede davanti ad una web app ed esegue operazioni di supporto sulle richieste, oltre a dirigere le richieste verso l’app. Può gestire pagine di errore, compressione, caching, servire i file, e bilanciamento del carico tra le altre cose.
Spostare le attività che non richiedono la conoscenza dello stato dell’applicazione per un proxy inverso libera Express per eseguire attività di applicazione specializzate. Per questo motivo, si raccomanda di eseguire Express dietro un proxy inverso come Nginx o HAProxy in produzione.